随着教育公平理念的深入发展,高校学生资助工作正从“普惠型”向“精准型”转变。传统资助模式依赖人工统计与主观判断,存在信息不对称、认定标准模糊、动态跟踪困难等问题,可能导致资源分配不均或遗漏真正需要帮助的学生。大数据技术的兴起,为构建科学、高效、透明的校园精准资助机制提供了全新的技术路径。本毕业设计旨在探讨如何利用计算机数据处理技术,设计并实现一个基于大数据的校园精准资助分析系统,以提升资助工作的科学性、公平性与效率。
一、 系统分析与核心需求
精准资助的核心在于“精准识别”、“精准帮扶”和“精准管理”。系统需整合校园内多源异构数据,构建全面的学生数字画像。数据源主要包括:
- 学工系统数据:家庭经济情况调查表、困难生认定记录、助学贷款信息等。
- 教务系统数据:学业成绩、课程出勤、奖惩记录等。
- 消费行为数据:校园一卡通在食堂、超市、图书馆等场景的消费流水,是反映学生经济状况的重要客观指标。
- 网络行为数据:校园网接入日志、数字资源访问情况等,可侧面反映学习投入与生活状态。
系统核心需求包括:
- 多维数据融合与清洗:建立统一数据标准,对来自不同业务系统的数据进行ETL(抽取、转换、加载)处理,解决数据不一致、缺失等问题。
- 贫困生精准识别模型:运用机器学习算法(如逻辑回归、决策树、聚类分析等),综合考虑显性(家庭申报)与隐性(消费行为)指标,构建量化评估模型,自动生成贫困生预警名单与困难等级评分,辅助人工审核。
- 资助效益动态评估:对受助学生的后续学业表现、消费水平变化等进行跟踪分析,评估资助措施的实际效果,形成“识别-资助-评估-反馈”的闭环。
- 可视化分析与决策支持:通过仪表盘、图表等形式,向资助管理人员直观展示整体资助态势、资金流向、预警信息等,为资源调配和政策优化提供数据支撑。
- 隐私与安全保护:严格遵循数据安全法规,对敏感信息进行脱敏处理,确保数据在采集、存储、分析、应用全流程中的安全与合规。
二、 系统设计与实现方案
本设计采用分层架构,通常包括数据采集层、数据存储与计算层、业务逻辑层和用户交互层。
- 技术选型:
- 数据处理服务:采用Hadoop/Spark生态处理海量数据,进行离线批处理和实时流计算。利用Spark MLlib或Scikit-learn等库构建机器学习模型。
- 数据存储:使用HDFS或对象存储存放原始数据;使用HBase、MySQL或PostgreSQL存储结构化的业务数据与模型结果。
- 后端开发:可采用Java(Spring Boot框架)或Python(Django/Flask框架)实现业务逻辑和API接口。
- 前端开发:使用Vue.js或React等框架构建管理后台,集成ECharts等图表库进行数据可视化。
- 关键模块实现:
- 数据预处理模块:编写脚本或使用Kettle等工具,定时从各业务系统同步数据,进行清洗、归一化和集成。
- 特征工程与模型训练模块:从集成数据中提取有效特征(如月均消费额、消费波动性、低消费天数占比、学业成绩趋势等),划分训练集与测试集,训练并优化贫困生识别模型。模型可定期自动更新迭代。
- 资助分析与推荐模块:根据识别结果和学生具体情况(如困难等级、学业需求、特长等),结合资助政策库,智能推荐合适的资助组合(助学金、勤工助学岗位、技能培训等)。
- 可视化与报表模块:开发数据看板,动态展示贫困生分布、资助覆盖率、学业进步对比等关键指标。支持按院系、年级、时间维度进行下钻分析。
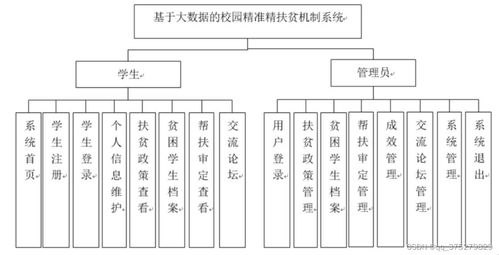
三、 毕业设计成果物:源码与论文文档
完整的毕业设计成果应包括可运行的系统源码(LW)和详细的设计文档。
- 源码(LW):应包含完整的项目源代码,结构清晰,注释规范,确保可部署和测试。核心算法模型部分需有详细的实现说明。
- 论文文档:需系统阐述项目背景与意义、国内外研究现状、相关理论与技术(大数据、机器学习等)、系统需求分析、总体与详细设计(含数据库设计、架构图、模块流程图)、核心功能实现过程、系统测试与结果分析(展示模型准确率、系统性能等)、与展望。论文应体现从问题分析、方案设计到编码实现的全过程逻辑。
四、 与展望
基于大数据的校园精准资助机制,通过数据驱动的决策方式,能够有效提升资助工作的精准度和管理效能,是智慧校园建设的重要组成部分。本设计将计算机数据处理服务与教育学、管理学需求紧密结合,具有实际应用价值。系统可进一步探索与心理健康数据、实习就业数据的关联分析,实现对学生成长的全方位、发展性资助,并利用隐私计算等技术在保障数据安全的前提下深化数据融合应用,最终构建一个更加人性化、智能化的学生成长支持体系。